
Transformers are Graph Neural Networks
https://thegradient.pub/transformers-are-graph-neural-networks/
Transformer 的出现推动了整个 NLP 领域。这篇博客旨在建立 GNNs 和 Transformers 之间的联系。
首先,两者都是为了完成“表征学习”(representation learning)。
NLP 表示学习
从高层次上,所有神经网络架构都将输入数据的表示构建为向量/嵌入,这些向量/嵌入对有关数据的有用的统计和语义信息进行编码。
对于 NLP ,传统上使用 RNNs 以顺序方式构建句子中每个单词的表示,即 one word at a time 。直觉上, RNNs 像一个传送带,从左到右地处理句子,最终得到每个单词的隐藏特征,传递给之后的任务。
![]()
Transformers 一开始被用于机器翻译,后来逐渐取代主流 NLP 中的RNNs 。它完全抛弃了循环,转而采用注意力机制区分其他所有单词的重要性,然后根据重要性加权求和所有单词线性变换后的特征。
分解 Transformer
这一节我们用数学表达式解释 Transformer 。
第 $l$ 层到第 $l+1$ 层将句子 $S$ 中第 $i$ 个单词的隐藏特征 $h$ 更新如下: \(h_i^{l+1} = \text{Attention} \left( Q^lh_i^l, K^lh_j^l, V^lh_j^l \right)\) 即 \(h_i^{l+1} = \sum_{j \in S} w_{ij} \left( V^l h_j^l \right)\\ \text{where } w_{ij} = \text{softmax}_i \left( Q^lh_i^l \cdot K^lh_j^l \right)\) 其中 $j \in S$ 表示句子中的单词, $Q^l$ , $K^l$ , $V^l$ 是可学习的线性变换权重。注意力机制并行地对句子中的每一个词进行计算,获得更新的特征。这也是 Transformers 相对 RNNs 的加分项。
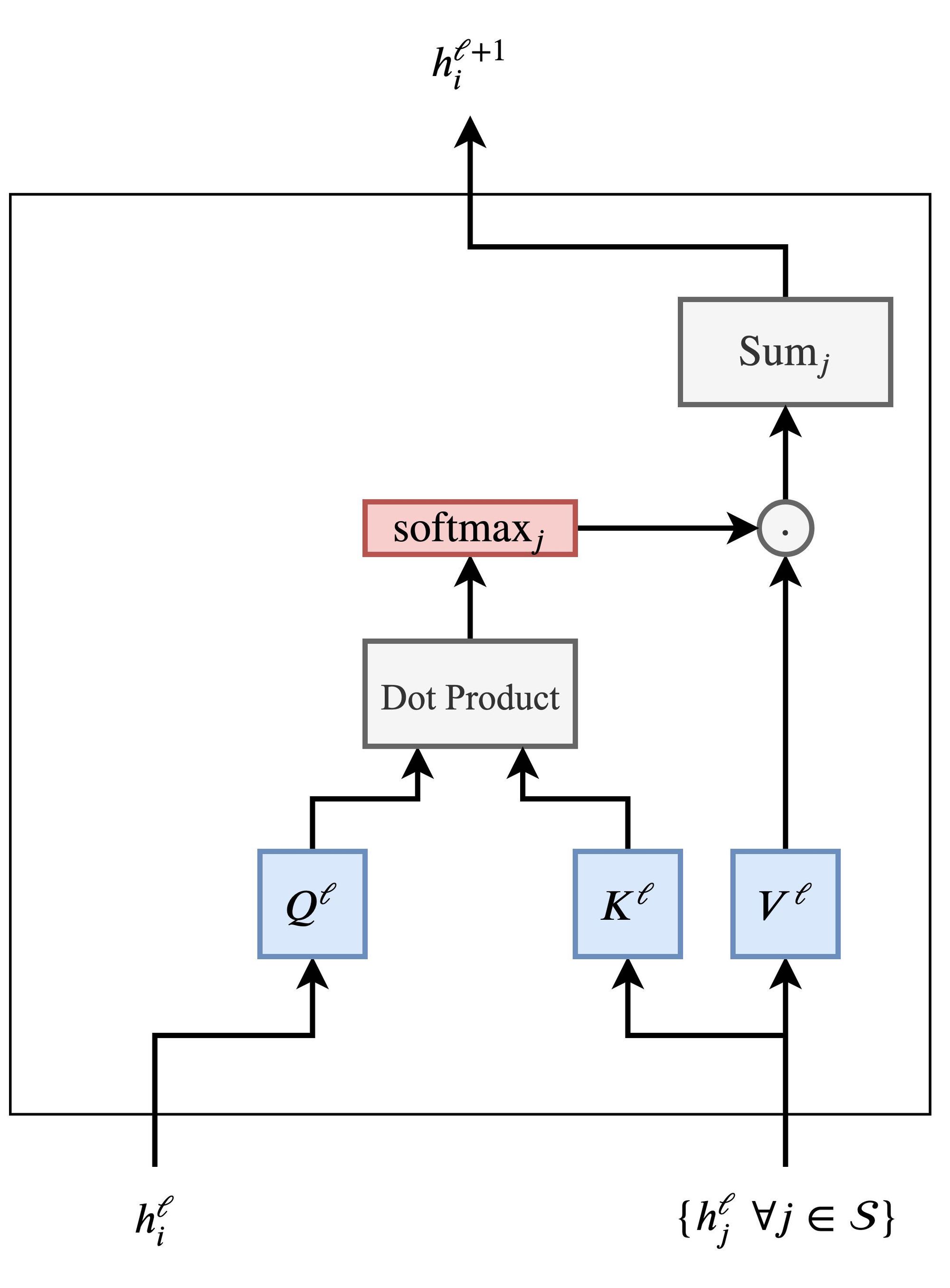
输入单词特征 $h_i^l$ 和句子中剩余的单词 ${h_j^l~\forall j \in S}$ ,我们通过点积计算 $(i,j)$ 对的注意力权重 $w_{ij}$ ,然后对所有 $j$ 应用 softmax ,最后加权求和所有 ${h_i^\prime}$ 。这一步骤对每个单词同时进行。
多头注意力
让这种简单的点积注意力机制发挥作用被证明是很棘手的。可学习权重的错误随机初始化会破坏训练过程的稳定性。
我们可以通过并行执行多个注意力“头”并连接结果来克服这个问题(每个头现在都有单独的可学习权重): \(h_i^{l+1} = \text{Concat } (\text{head}_1, \dots, \text{head}_K) O^l\\ \text{head}_k = \text{Attention} \left( Q^{k,l}h_i^l, K^{k,l}h_j^l, V^{k,l}h_j^l \right)\) 其中 $Q^{k,l}h_i^l$ , $K^{k,l}h_j^l$ , $V^{k,l}h_j^l$ 是第 k 个注意力头可学习的权重, $O^l$ 是一个向下投影,来匹配跨层的 $h_i^{l+1}$ 和 $h_i^l$ 的维度。
多头允许多头必要地 hedge its bets ,从不同角度观察前一层的隐藏特征。
尺度问题
推动最终 Transformer 架构的一个关键问题是,在注意力机制之后的单词特征可能处于不同的尺度或量级。这可能是因为一些词具有非常集中或者分散的注意力全中,或是多个注意力头拼接后的特征范围很大。
按照传统的 ML 智慧,在流程中添加规范化层似乎是合理的。
Transformers 中有三种规范方法: (1) LN ,在特征级别规范化并学习仿射变换。 (2) 对点积除以特征维度的平方根。 (3) 具有特殊结构的按位置 2 层 MLP 。多头注意力之后,作者用可学习的权重将 $h_i^{l+1}$ 映射到一个极其高的维度,然后经过 ReLU 非线性处理,再映射回原来的维度并进行正则化: \(h_i^{l+1} = \text{LN}(\text{MLP}(\text{LN}(h_i^{l+1})))\) (3) 可能有点难以理解。根据 Jannes Muenchmeyer 的说法,前馈子层确保 Transformer 是一个通用逼近器。 因此,投影到非常高维空间、应用非线性并重新投影到原始维度允许模型表示比在隐藏层中保持相同维度更多的函数。
Transformer 层的最终图片如下所示:
![]()
图中省略了多头注意力子层和前馈子层的 residual connections 。
Transformer 架构也非常适合非常深的网络,使 NLP 社区能够在模型参数和数据方面进行扩展。
GNN 构建图的表示
GNNs 或 GCNs 通过 neighborhood aggregation (or message passing) 构建图数据中的节点和边的表示。Neighborhood aggregation (or message passing) 中每个节点通过聚合自身邻居特征来更新自己的特征,以表示它周围的局部图结构。堆积多个 GNN 层允许节点的特征在整个图中传播,即从邻居传播到邻居的邻居,以此类推。
最常见地, GNNs 在 $l$ 层更新节点 $i$ 的隐藏特征 $h$ 如下:非线性转换节点自身特征,再加上邻居聚合特征。 \(h_i^{l+1} = \sigma \left( U^lh_i^l + \sum_{j \in \mathcal N(i)} \left( V^lh_j^l \right) \right)\) 其中 $U^l$ , $V^l$ 是 GNN 层可学习的权重矩阵, $\sigma$ 是非线性函数。
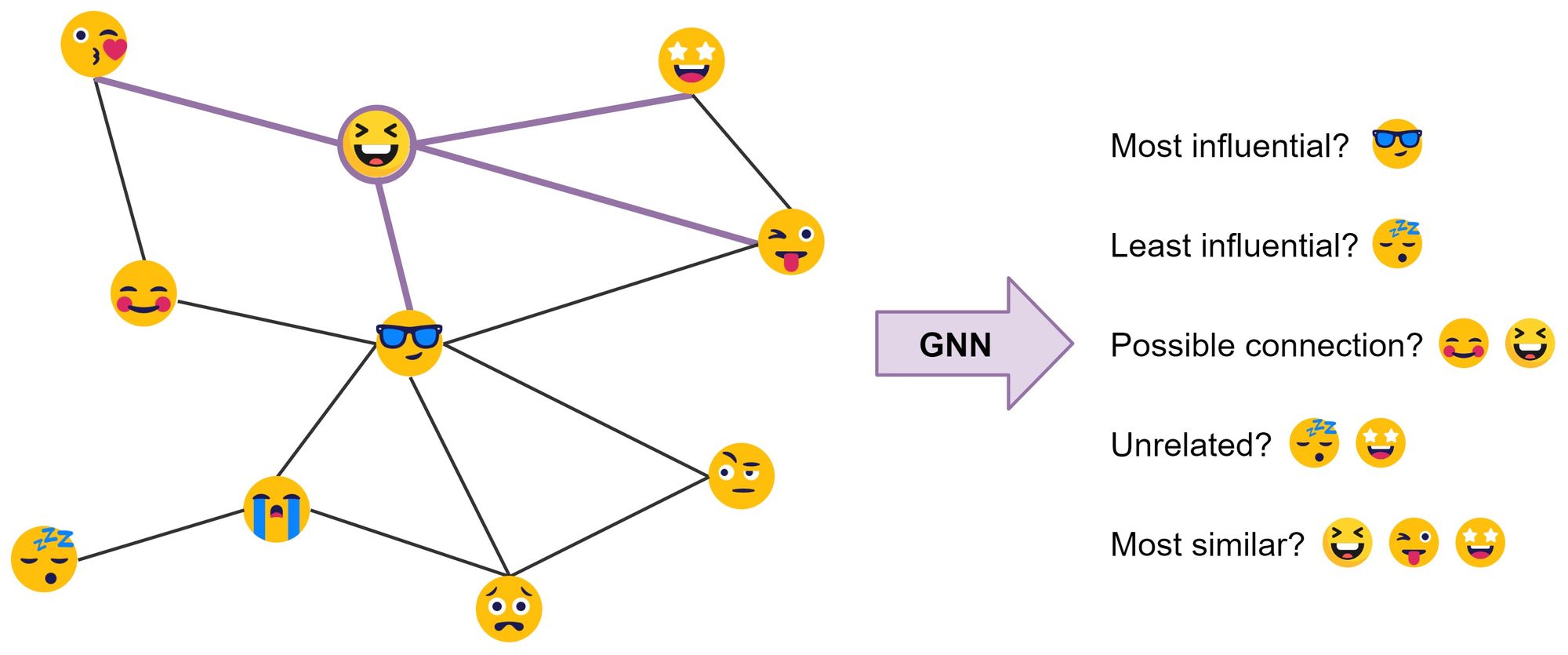
上图中, $\mathcal N(😆) = { 😘, 😎, 😜, 🤩 }$ 。
公式 (5) 中的求和可以被其他输入大小不变的聚合函数替换,如 mean/max ,或者注意力机制。如果我们把聚合函数替换为注意力机制,并采用多个并行的头进行 neighborhood aggregation 我们就得到了 GAT 。增加正则化和前馈 MLP , voila ,就是 Graph Transformer !
句子是全连接的单词图
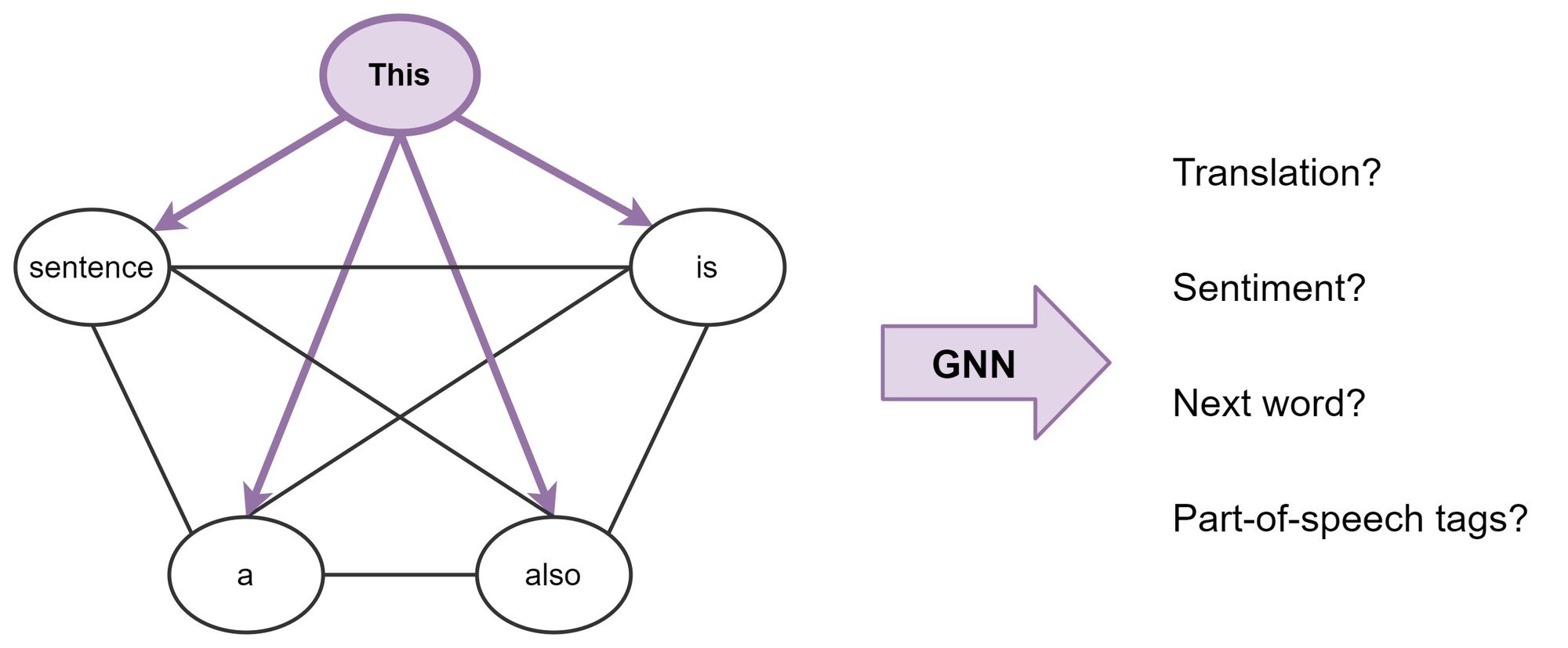
于是我们可以用 GNN 来构建每个单词的特征,然后我们可以使用它来执行 NLP 任务。这就是 Transformer 在做的事情:具有多头注意力的 GNNs 进行 neighborhood aggregation 。只是 Transformer 同时处理句子中的所有单词,而 GNN 只处理一阶邻居。
重要的是,各种针对特定问题的技巧——例如位置编码、因果/屏蔽聚合、学习率计划和广泛的预训练——对于 Transformer 的成功至关重要,但在 GNN 社区中却很少出现。 同时,从 GNN 的角度看待 Transformers 可以启发我们摆脱架构中的许多花里胡哨 (bells and whistles) 。
思考
句子是全连通图吗?
在统计 NLP 和 ML 之前,像 Noam Chomsky 这样的语言学家专注于开发语言结构的形式理论,例如句法树/图。 Tree LSTMs 已经尝试过这一点,但也许 Transformers/GNNs 是更好的架构,可以将语言理论和统计 NLP 两个世界结合在一起? 例如,MILA 和斯坦福大学最近的一项工作探索了使用语法树来增强预训练的 Transformer,例如 BERT [Sachan et al., 2020]。
长距离依赖
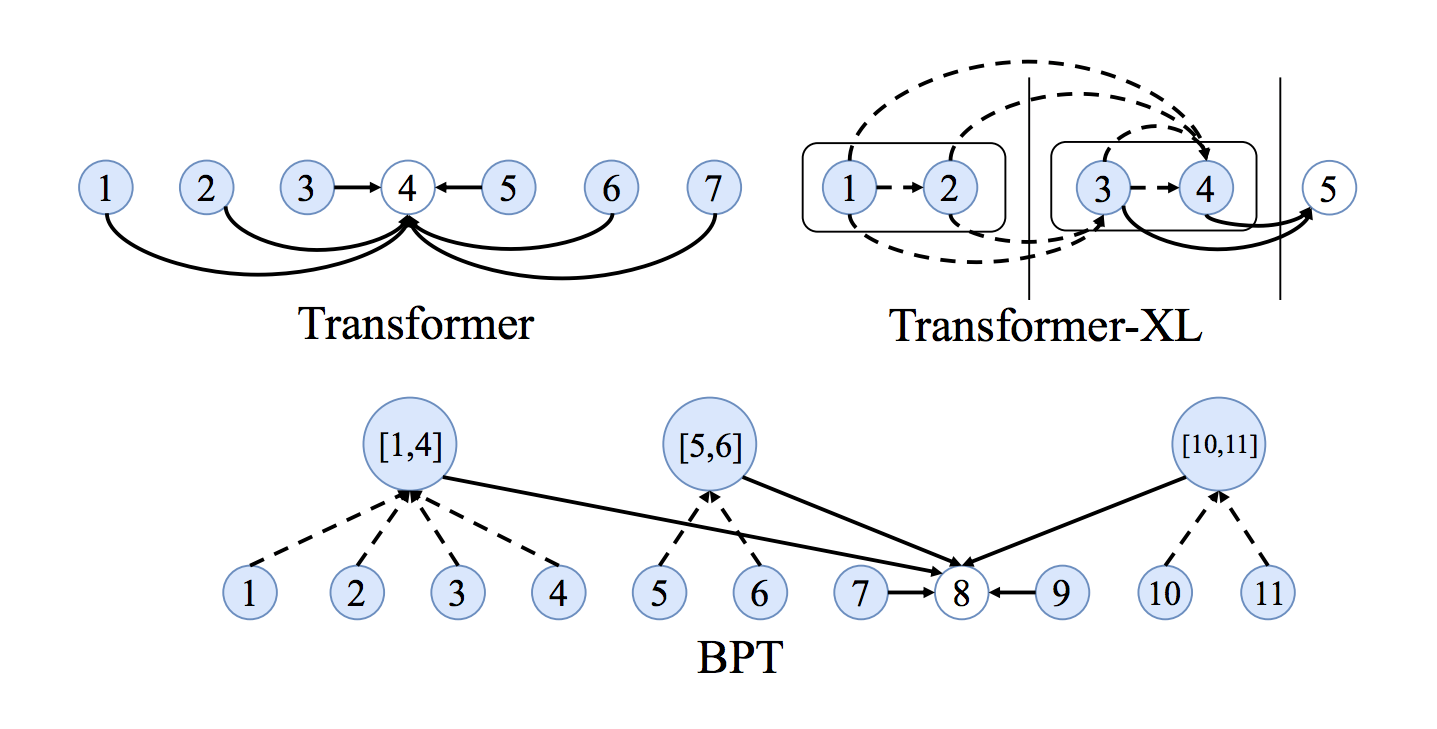
全连接图的另一个问题是它们使学习单词之间非常长期的依赖关系变得困难,因为边数随节点数呈二次方关系。随着 $n$ 的增加,事情逐渐不可控。
NLP 社区对长序列和依赖问题的看法很有趣:使注意力机制在输入大小方面变得稀疏或自适应,在每一层中添加递归或压缩,以及使用局部敏感散列来进行有效注意力都是有希望的新想法,以更好地实现 Transformer 。
看到 GNN 社区的想法融入其中会很有趣,例如,用于句子图稀疏化的二进制分区似乎是另一种令人兴奋的方法。 BP-Transformers 递归地将句子分成两部分,直到它们可以从句子标记中构造出分层二叉树。 这种结构归纳偏差有助于模型以高效记忆的方式处理更长的文本序列。
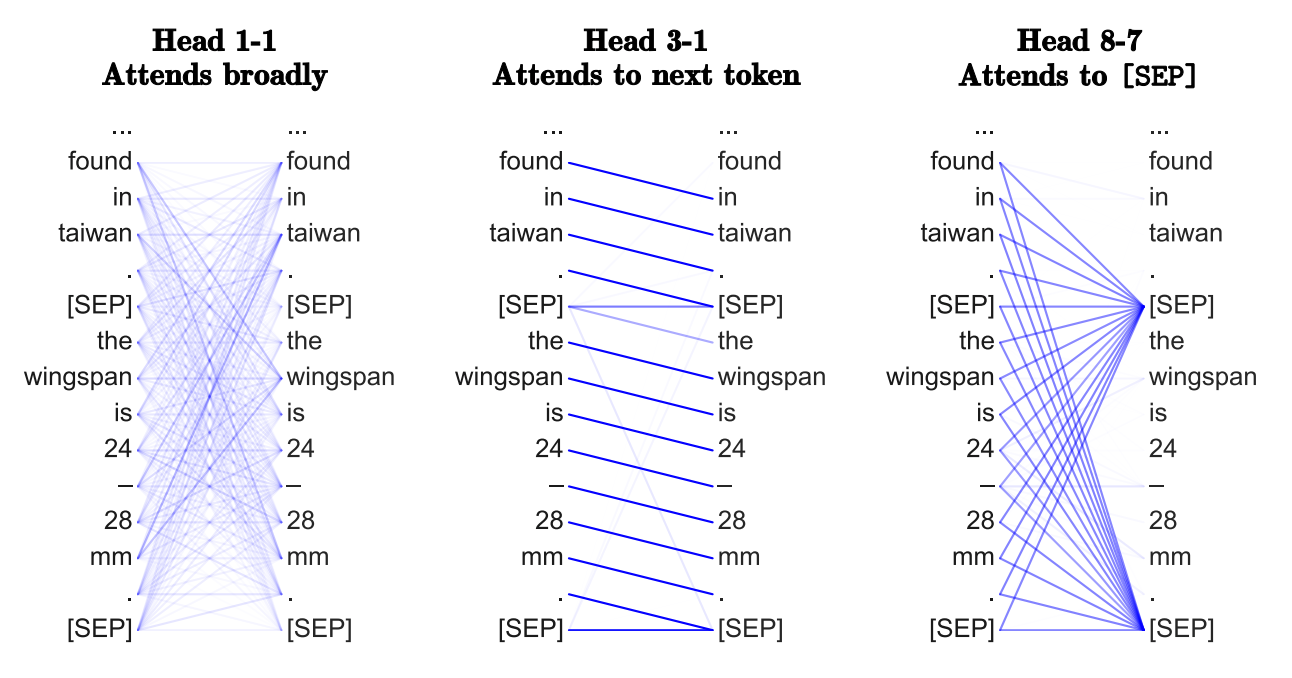
Transformer 学习语法吗
Transformer 最基本的开始是通过赋予单词对注意力,可以学习到类似于任务特定的语法。不同的头可能在寻找不同的语法性质。
在图方面,通过在全图上使用 GNN,我们能否从 GNN 在每一层执行邻域聚合的方式中恢复最重要的边——以及它们可能包含的内容? 我还不太相信这种观点。
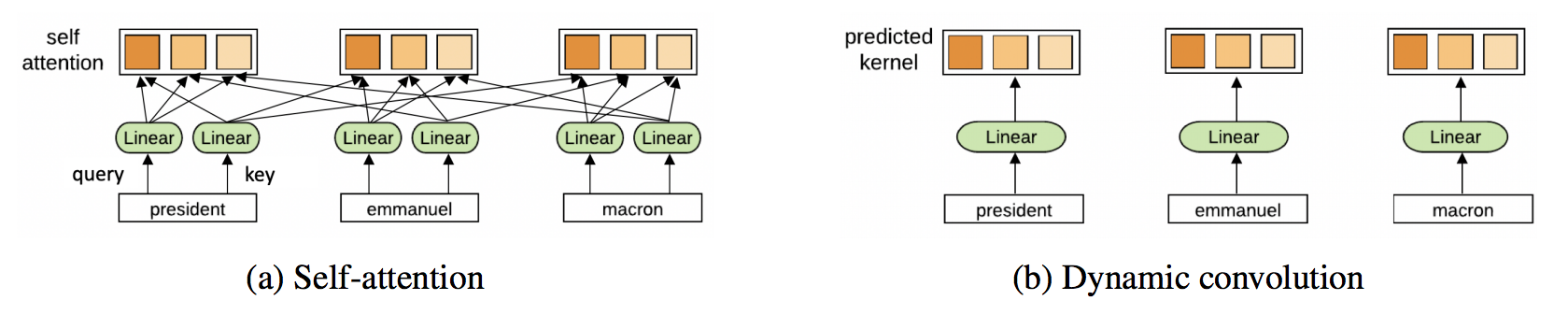
为什么多头注意力?为什么注意力?
拥有多个注意力头可以改善学习并克服糟糕的随机初始化。例如,论文表明,在训练后可以“修剪”或移除 Transformer 头部,而不会对性能产生重大影响。
多头 neighborhood aggregation 机制被证明很有效: GAT 使用多头注意力机制, MoNet 使用多个高斯核聚合特征。尽管设计用于稳定注意力机制,多头技巧能否成为提升额外模型性能的标准?
此外,如果我们不必计算句子中每个单词对之间的成对兼容性,这对 Transformers 来说不是很好吗?
另外, Transformer 能从完全放弃注意力中受益吗?Yann Dauphin 和合作者最近的工作提出了另一种 ConvNet 架构。 Transformers 最终也可能会做类似于 ConvNets 的事情!
为什么很难训练 Transformers ?
阅读新的 Transformer 论文让我觉得在确定最佳学习率计划、预热策略和衰减设置时,训练这些模型需要一些类似于黑魔法的东西。 这可能只是因为模型如此庞大,所研究的 NLP 任务如此具有挑战性。
最后,我们真的需要多个昂贵的成对注意力、过度参数化的 MLP 子层和复杂的学习计划吗? 我们真的需要具有大量碳足迹的大型模型吗? 对手头的任务具有良好归纳偏差的架构不应该更容易训练吗?
如果觉得本教程不错或对您有用,请前往项目地址 https://raw.githubusercontent.com/Harry-hhj/Harry-hhj.github.io 点击 Star :) ,这将是对我的肯定和鼓励,谢谢!
作者:Harry-hhj,Github主页:传送门